
石が貯まったので兹白さんのガチャを回してなんとか1凸に。餅を持たせてあげたい気持ちはありますが…。
日記的なものはうっかり何処かで詰まるとその後書けなくなるのが悩ましい。
というのも純粋にファイルの作成日(frontmatter の date)で並んでるのでテキトーな順で書くと変な順番になってしまうのですよね。と思ったけど date で並び替えだからそこだけ手で直しておけば大丈夫でした(自己完結)
]]>
石が貯まったので兹白さんのガチャを回してなんとか1凸に。餅を持たせてあげたい気持ちはありますが…。
日記的なものはうっかり何処かで詰まるとその後書けなくなるのが悩ましい。
というのも純粋にファイルの作成日(frontmatter の date)で並んでるのでテキトーな順で書くと変な順番になってしまうのですよね。と思ったけど date で並び替えだからそこだけ手で直しておけば大丈夫でした(自己完結)
]]>ぴあアリーナMMより何となく近く感じるのと日産本社ビルのとこのスタバで座れるのが良いですね。


今回はS席でしたがその中でも中央前の方だったので全体を見れてだいぶ良い席でした。機材席が見えるので何やってるのか気になる…。

トロッコ出来るのかーと思いつつ、一瞬少しカクついていたので実体は流石に動かずリモート配信的な仕組みっぽそう。実体は何処にいるんだろうと前から気になっていたけど、肉声で声を届けるというところがあったのでステージスクリーン裏とかなんでしょうか。
]]>なんかラウマやオロルンとかもそうだけど見た目からとっつきづらそうに見えるけど、普通に意外と優しい人が多い。

商品トップ:X8 series X8900R|REGZA<レグザ>
ただ、ここに至るまでには紆余曲折が…
元々は27インチのディスプレイがあって、それに Switch や Xbox Series S がつながってるという形になっていたのですがいくつか問題がありました。
まずそんなに新しくないディスプレイなので HDMI が1系統しかない、スピーカーがない、PC 向けなので HDMI-CEC未対応、特に一番大きい問題だったのは27インチだと2m近く離れるとゲーム画面の文字が読めなくなるというところ。
というわけで27インチ以上のサイズのディスプレイかテレビを探すかとなったのですが、32インチの液晶も家にあるので離れて確認したところ2m離れるとまあまあ厳しい。昨今の UI に文字の多いゲームは辛そう。ということで40-43インチかなーというところでそうなると選択できるものは必然的にテレビになります。
ただ50インチ以下のテレビというのは微妙なラインで4KとフルHDのモデルが混在し、お値段もインチ当たりだと55インチなどに比べて高くなるというところ。とはいえ50インチ以上を今ある机の上に置いたら倒れてきて死待ったなし…ということで43インチ当たりかなと考えていました。まあこのクラスなら10万以下に収まることも多いですし。
そんなわけで家電量販店でちょこちょこ見ていたところよさそうだったのがソニーの KJ-43X80L と REGZA の 43Z670R というモデル。一番に重視したのは最低限視野角の色変化がひどすぎないことだったのですが、これらは視野角による色変化が比較的穏やかでした。このあたりは店頭で見比べるとよくわかりますが、極端に安いものは斜めから見るとすぐに白くなったりします。TCL とか Hisense とかは大体そう。REGZA も価格帯で違います。
ソニーのほうは視野角以外は平凡なのでどちらかといえば割高で、REGZA は 120Hz 対応しているのと、2画面モードというものがあって {地デジ,BS,HDMI}+{地デジ,BS,YouTube,AirPlay} のように組み合わせて表示できるテレビで2窓できるという面白機能があるのが特に気になりました。Video & TV SideView もあってソニーのテレビしか買ってこなかったのですが、面白機能には惹かれざるを得ません。
これで決まりか?と思っていたところ、そもそも机は実質物置なので捨てて壁寄せスタンドにすればよいのでは?というアイデアが降ってきて、壁に寄せるなら別にサイズが大きくなっても行けるのでは?からのじゃあ50以上にできそうということで55インチを検討することに。
そこで REGZA の55インチを考えていたところ、1世代前の 55X8900N というモデルがなんと大手ネット通販サイトで限定週末特価13万円台で売られているのを発見、1世代(1年)違いなら大差ないはず!と即購入しました…が、実は2画面モードは2025年モデルつまり現行世代からの搭載だということに気づき、即キャンセルとなりました。2画面モードにこだわらなければ大変お買い得だったと思います。
結局 55X8900R という現行世代を買うことにしたので思ったより出費してるような気がしますが、長く使うことを前提にしたのでまあ良しとします。ちなみにいざ買おうと思ったら値引きが終了した翌日だったので、他店ではこれぐらいでしたので何とかなったりします?って交渉したら安くなった上にポイントも多くしてくれたので良かったです。ネットにはない人間の温かみ…。
テレビスタンドは EQUALS の WALL V3 Compact というものを買いました。セットで買うと値引いてくれるのも量販店のいいところ。後になって気づいたのは掃除機のスタンドが同じシリーズだったということでした。(買ったのは8年ぐらい前だし全然知らなかった)
テレビスタンドはWALL~ V3 COMPACT | EQUALS(イコールズ)
都合により自力設置としたのですが思い返せばテレビを持ち上げるときにひやひやするのと、梱包材を処分するのが大変なのでできるなら業者にお願いしたほうがいいなとかはありますがそのぐらいでしょうか。なお1人での作業は危険だし不可能だと思ったほうが良いです。
ところで届く前に設置時に破損したらいやだなと心配になって、設置に関する動画ないのかなと思って探していたら REGZA の公式チャンネルにぴったりの面白動画があったのでオススメです。
【真実やいかに?!】液晶パネルVS有機ELパネル 強度の疑問を徹底検証
【後悔先に立たず】設置から地震対策まで! パネル破損を防ぐテクニック大公開
2画面モードはゲームしながら YouTube も流せるのでいいですね。
また、2画面モードで可能な組み合わせは上記の通り {地デジ,BS,HDMI}+{地デジ,BS,YouTube,AirPlay} であり、YouTube + YouTube はできないのですが Chromecast や FireTV のようなものを HDMI に挿せば YouTube を並べられます。同時視聴もできて便利。
他のメーカーのテレビの2画面機能についてもいくつか見てみたのですが、HDMI+YouTubeのようなことができるどころか HDMI にすらできないというメーカーもあり、REGZA の2画面モードが一番柔軟そうです。それでも十分制限がありますが。なお LG はシステムがモッサリしすぎてて2画面機能の前に論外でびっくりしました。そういえば Smart Monitor シリーズも同じ怪しさがありましたね…。
あとこれ、日常で2画面モードにし続けてると多分有機 EL 的にはよろしくなさそうな予感がしました。
ソニーのテレビの良いところとして Video & TV SideView というリモコンアプリの存在があるのですが、REGZA にはなさそうなのかなーと思っていたところ「RZ ハイブリッドリモ」というアプリでスマホをリモコン化できました。Video & TV SideView みたいに番組表などはありませんがまあ。
他にも HomeKit 連携と Google アシスタント連携があるので iOS の Home アプリや Google Home アプリからもなんとなく操作できます。
さすがに有機 EL なので視野角の広さはよきです。ただなんか最小輝度でもう少し暗くなっていただいてもよかったかも…昨今テレビのパフォーマンスとして測られるところに輝度があるとはいえ。まあもしかすると比較対象の普段使っているで A9F が劣化してて暗くなりつつある説はあります。
ちなみに BRAVIA A9F は7年ぐらい使っていて、最近近くでよく見たところ結構パネルが劣化していて縁のあたりがうっすら白っぽくなったり、ぽつぽつドット欠けが生まれてて有機 EL の劣化は結構わかりやすいものだと思ったところでした。
テレビのスピーカーは「ああ、テレビのスピーカーだしね…」域からは出られないのか感…致し方なし。いつか適当にサウンドバーを買ってもいいかなとは思ってますが急いで買うほどでもなく。
]]>数日前に買っていた POP MART の Genshin Impact Gathering Chibi シリーズが届きました。一応シークレット以外はコンプリート。

その時には普通のバラ売りとアソート(全部入り)は売り切れていたのですが、POP NOW というガサガサしながら選んで買う方はまだあったのでポチポチと。POP NOW は箱をシェイクして中に何が入っていないかというヒントを得られて、ただランダムを買うより狙える可能性があるという仕組み。ある意味優しいかも?
一つのボックスから選ぶのですが、まとめ買いもできて6個まとめて買えばコンプできるので実質アソートと同じ買い方ができる…ということに気づいたのは何個か引いた後だったので結果的にムダに被りを生んでしまって学びがありました。コロンビーナとフリンズ狙いだったもののなかなか出なかったのですよ。
一昨日あたりに楽天の公式通販とかでも買えるようになったタイミングで知った人が増えたのか POP NOW の方も売り切れたのでセーフです。
YouTube Premium の契約いつの間にか切れていて CM が表示されて気づくマン。年間契約って自動更新ではないから毎度いつの間にか切れてたってなっている気がする。
]]>幻想シアター マスターモードを初めてやってみたけど星10クリアできました。よかった。

後半に向けて戦力温存するために前半に使ったことのないお試し星5と使い慣れない星4キャラでこなすのがしんどみあります。月諭モードはキャラが足りないので無理です表示。ですよね。
エンドフィールドを少しずつやってるけどみんなこんな難しいゲームやってるんですか…?
]]>
グラフィックはよく出来てて Unity でも頑張ればどうにかなるというか下手な UE 製より全然よい感じがします。まあ魔改造中華 Unity なのかもしれないし、レンダリングパイプラインを改造しまくっただけなのかもしれないですがそこは謎。いずれにしてもキャラクターがちゃんと綺麗でかわいいのは素直にすごい。スマホだと 45fps がデフォルトなのもかしこい。

ゲームの内容はどうでしょう…なんというか出来ることが盛り盛りなのでなかなかしんどいかもしれません。デイリーはそんなに大変ではなさそうですが。
例によって大陸ゲーあるあるとして漢字や独自用語が多いのでむずかしい…今思えばファルシのルシがコクーンでパージとか大した事なくなくないですか?
あと原神を始めた頃にも思ったこととして、UI がスマートフォンやキーボード/マウスに最適化したものをベースとしているので一般的なコンソールゲームのドリルダウン式メニューやリスト表示ではなく1画面にインタラクションできるものが撒き散らされているものが多くなりがちです。その結果としてコントローラー向けにはキーにあらゆるアクションが割り当てられてなかなか複雑なシロモノとなります。
で、エンドフィールドは機能というかやれる事がただでさえ多いのとデザイン的にオシャレな代わりにわかりにくい部分があるので輪をかけてなんだか難しい感じがします。おぼえられにあ。
まあせっかくなのでしばらくちまちま続けるかも。
ファンクラブイベント、昼夜2公演当たったのはいいけど17,380円とかで最近のチケットは高くなったものだと軽くショック。
鍛錬の道により、ついにティナリ師匠完凸。
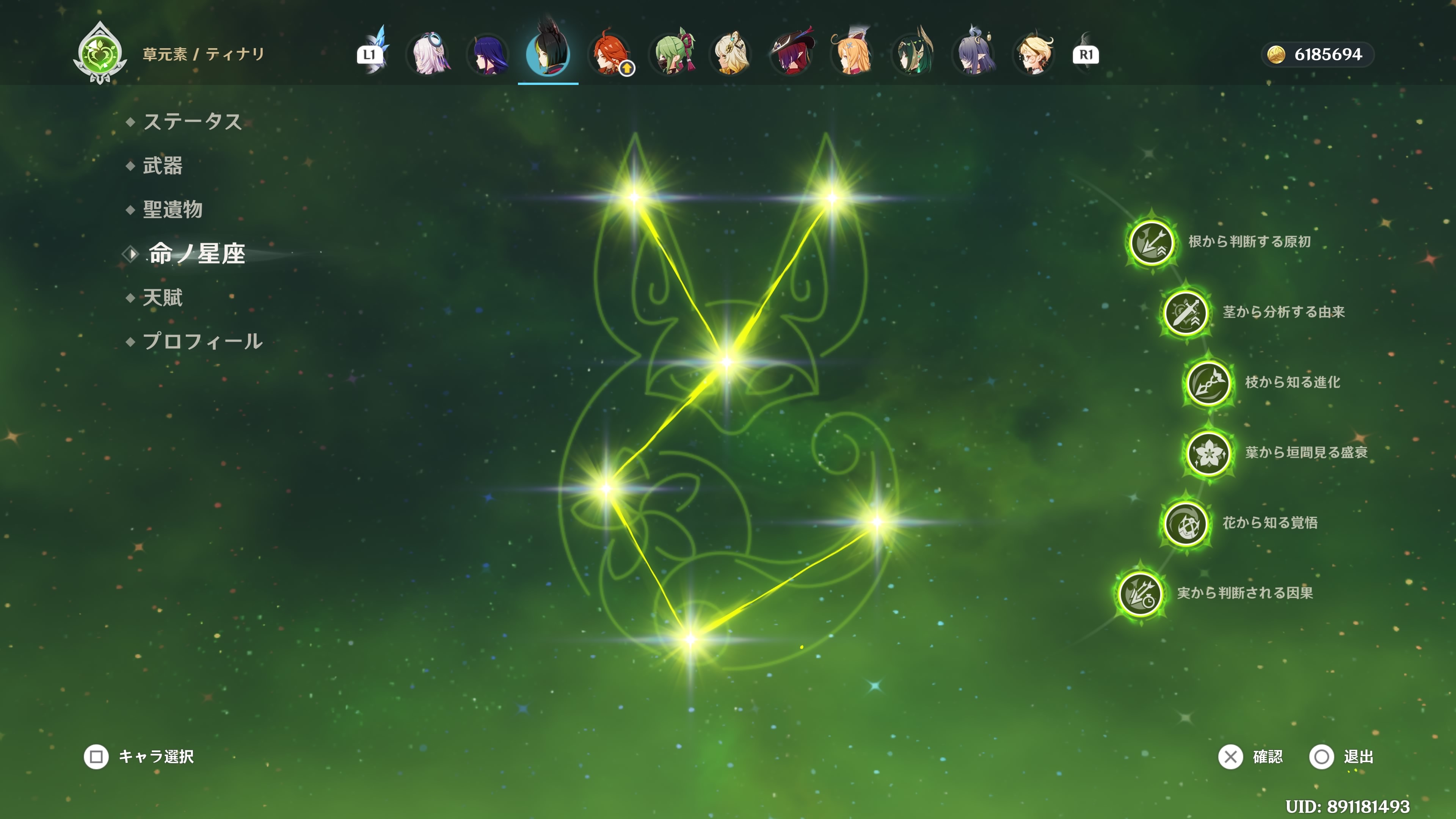
初めて手に入れた⭐︎5キャラで、しばらくメインアタッカーとして使っていたので感慨深い。その後もすり抜けてやって来た回数が1番多かったわけだったりして縁があります。
]]>
それはそうと旅人の新衣装はイベントカットシーンには反映されないのがモデルも新しくなってるのにもったいない。…というのもあるけどカットシーンと会話パートで旅人にスイッチするパターンでチグハグになるのがちょっと気になる。
]]>
多分このお店に限らないと思うのですが何という申し訳程度のコラボ…。


養命酒養生テラスSHIBUYAの呼び込みをまたやってましたのでパシャ。

第7幕終わった…原神はいつも会話パート長いけどこれ輪をかけて長いのでは。

それはそれとしてコロンビーナの素材が集まって Lv.90 になったのでヨシ。まだ博士倒してないので天賦は上がりません。
]]>

ストックされていた石はほとんどが無事溶けてバッバイ。というか大体ほぼ天井みたいな感じだったので最近の中ではなかなか渋かった…。
コロンビーナはガチャ演出も違うし、立ち絵も一枚絵になってるし、空月の祝福も変わるし、全体的にかなり力が入っているのが感じられます。モーションも全然違うのでフィールドで操作してるだけでもちょっと楽しい気持ちになりますね。
あとはサンドローネを何としても実装して欲しいが、なんか実装されないのではないかみたいな予感がなくもなく…。ちょっと前までは逆にコロンビーナが実装されないかと思ってたけど。まだ新ストーリーをやってないのでわからないものの声を当ててる本多さんが配信してるぐらいだから早期退場はないものと信じています。
]]>幽境エクストラは下手すぎて無理かと思ったけど全てがギリギリタイムでクリアできた…。螺旋12層は半月ぐらい前にやって3問で止めてたので最後やったらできたのでヨシ。螺旋はバトルシップが固くて厳しかった。
コロンビーナの素材は新素材以外は大体揃ったような気がする。
スカイツリーのあたりに行ったので、なんやかんやあって蔵前のダンデライオンチョコレートへ。
何回か訪れているけれどいつも平日午前中だったので、休みの日の夕方近くの混み具合は謎でしたが少し外で待つ程度で入れたのでよきでした。イートインではハウスホットチョコレートとザッハトルテをいただきました。

で、持ち帰りでいつものようにクッキーアソートメントを。ホットチョコレートミックスとかチョコ系のものも気になるのだけど、直前にチョコを摂取しているのでまあいいかという気持ちになりがち…。

その後もなんやかんや用事を済ませて、最後は東京駅へ。今東京駅のキャラクターストリートのあたりで hololive production OFFICIAL POP UP SHOP というポップアップストアやってるのでそこへ。土日は整理券が必要ですが今日はフリー入場なので思い立った勢いで行くのです。
「hololive production OFFICIAL POP UP SHOP」東京駅一番街にて開催決定! | ホロライブプロダクション
とりあえずアクスタを買ったりとかしました。


東京駅の TBS ショップにはロイヤルファミリーのロイヤルホープ(ウマ娘コラボ)のアクスタがあるので折角ですしお買い上げ。ロイヤルファミリーのアクスタは売り切れてたので残念。


なんか展示が昔来た時から色々と変わっていて、ミュージアムショップもカフェも全然かわってた。展示は物よりもストーリーや体感型みたいなものが増えた気がしますね。

インターネット物理モデルが無くなった代わりに、というわけではないとは思うけど災害の概念モデルみたいなものがあったものの、結構抽象度が高いのでなんとも…。コンピューター系の展示もメディアアートっぽいし、やはりインターネット物理モデルが残っていて欲しかったですね(老人)。
100億人でサバイバル | 日本科学未来館 (Miraikan)
お台場の Diver City に寄って、さらにアクアシティまでいってポムの樹でごはん。ポムの樹、1番小さいサイズの SS が茶碗 1.7 杯って書いてあって上のサイズは一体どうなってしまうのかという疑問。


アクアシティに入ったらたまたまグッスマのポップアップストアが。ちょうど今日かららしい。折角なので HELLO! GOOD SMILE の大神ミオ、猫又おかゆをバイナウしました。このシリーズはいくつか持ってるけど、今後さくらみこ、原神シリーズとかも出るし、ゼンゼロのアンビーが進行中らしいので楽しみです。
GOOD SMILE POP UP STORE in アクアシティお台場|グッドスマイルカンパニー

なんか cho45 さんのところを見てて、ブログを作り直したい気がしてきたというか、GitHub 管理じゃなくてもいいし、普通の動的サーバーサイドレンダリングでもいいので好きに作ればいいのではないかみたいな気持ちが湧いてきた。
Web 管理画面があればいいという都合上、裏側が GitHub でいいことってバックアップと一括置換できるぐらいなもので、メディアを扱いたいとか記事や日ベースで扱いたいとかだと逆に面倒だったりだし。
]]>待ってもいいのでということで最短で予約して、処置してもらったけど結果的にだいぶ良くないところまで進行してたので神経バッバイ…。
3ヶ月おきの定期検診で通ってたのに…どうして…と思って聞いたところ、虫歯はあるけれど神経は繋がってないので原因はよくわからないがそういうこともまれに良くある、という話でした。まあ前から甘いものや冷たいものがしみることがあったので兆候はあったのかも。
そして保険治療の支払いについにクレジットカード使えるようになってたのですばら。マイナンバーカードも iPhone でいけるようになってたのもヨシ。
夕飯食べていたら銀歯が外れて最悪すぎるのですが。どうして…。必要だったのは厄除けのお守りではなくご祈祷とかだったかもしれません。
はじめてのデジタルアイデンティティ ―Webサービスに欠かせない認証・認可・ID管理が発売となった通知が来たのでバイナウ。
]]>
晴れていたこともあり、参拝するのは去年よりもだいぶスムーズで寒すぎたりもなかったのでよきです。

おまもりは心身健康的なやつと厄除け、除災招福守というリミテッドエディションみたいなやつの3つを購入。どのお守りを買うか見ていたら福守と開運というのがあって、どう違うのかなと思って調べてみると福守は幸福を守る(例えば今幸せな生活をしているなら長続きしますように的な)、開運は運を呼び込むみたいな違いがあるとか。なるほどですね。
おみくじは引くまで吉とか書いていないタイプだったことをすっかり忘れていて、引いてからそういえばありがたい言葉がかいてあるやつだったーとなったり。何故か誰も引くまで気づいてなかった…。で、引いたおみくじの内容は「言葉づかいに気をつけましょう」というもので、このソーシャルメディア時代にうってつけのお言葉でした。

CD は一般流通ではないものとか、iTunes Store やサブスクにないようなものもあるので適当に残しておかないといかなかったりがちょっと面倒…。あとは本もマンガと技術書を処分したい…。
Windows の Auto SR (Automatic Super Resolution - Microsoft Support)、いつの間にか 1920x1080 を指定できて動くようになってる気がする。どこにも書いてないけど。
ただやっぱりこの補完は機械学習による生成系に良くある細部がびみょくなるというか、エッジがちょっと気になる感じなので文字とかが結構気になることがあるので好みはあるかなー。
今年は hololive production COUNTDOWN LIVE 2025▷2026 で終わり。なんか今年の年末はホロライブ見てばかりだったような気がする。
]]>何も考えずにフィッシュルを最初の方で使ってしまってドレイクでダメかと思った…。
夜は特にテレビを見るでもないのでみこちの JumpKing とフブさんのサイコロ耐久を流し続ける。みこちの「うー、パッ」とフブさんのカラカラ音が環境音によき。
昼間変に寝てしまって眠れなかったのでなんやかんや朝7時ぐらいまで聴いてしまった。(みこちがフブさんとこから抜けたあたりで寝落ちた)
同意といい VTuber 忍耐力のバケモノじゃないとやっていけないのだろうか…。
]]>思い出が自動で流れる「みてねおもいでフォトフレーム」が新登場みてねプレミアム会員なら写真・動画も無制限、12月1日(月)より販売 | ニュース| 株式会社MIXI
キーボードが Gboard だったり Android ベースのデバイスっぽい、というか触るまでタッチパネルで操作することができると思っていなくて、設定は全部スマートフォンからやるのかと思ってました。そんなことはなかった。
動画は自動で再生されるけど、音量はゼロにしておいた方が良さそう。夜中になったらどうなるのかと思ったら明るさセンサーなどはないので時間が来たら時刻表示になるとかという感じ。
まあ、単機能ではあるもののおじいちゃんおばあちゃんの家に置く、みたいな感じならこんなものでよさそう。
]]>部屋が狭すぎるので物を預けているけど、大半はフィギュアなのでは説。まあ置いておくことができないので仕方ないですが。
有馬記念はみこちを信じて買ったので、コスモキュランダ入ってなくてお金バッバイ。当のみこちは135万円を吹き飛ばしていた。
]]>マリンタワーの横を通ったことがあるらしいのだけど何も覚えていなかったという…。タワーのイメージが東京タワーとか東京スカイツリーだったので意外とこじんまりしているなという印象ですが、多分そのイメージがデカいものすぎる説はある。


展望フロアからは横浜を一望できて、そんなに混んではいなかったので平和でよきですね。カメラを持っていったのだけどバッテリーが4%とかだったのでほとんど撮らず。


展望フロアにはアイノ、フリンズ、ラウマのパネルが置かれていました。


あとは展望フロアに行かなくてもまわれる2階にはパネルと模型が展示されていました。




夜行くと展望フロアでムービーが流れるらしい(既存映像だけど)のでもう少し雰囲気が違ったかもしれないけど、音楽を流すぐらいしてくれてもいいのにな感は否めなかったですね…まあなんか展示されているのでコラボではありましたが…。
雑炊とかばかりだった食事を戻しはじめたり。あげものや辛いものとかはまだ避けていますが。消化のことを考えてよく噛んで食べるようにしているので、普通の人よりも少なくしているにも関わらず食べるのに1.5倍以上の時間がかかるのもなかなか厄介ですね。
ガムテープやクラフトテープを切るためのテープカッター(ニチバン HCP-50)をバイナウ。クラフトテープだと特に良さそう、というか最初はそのつもりだったけど結局ガムテープで使っています。(クラフトテープを捨てた)
ハンドカッター HC-50/HC-75/HCP-50|外装用|ニチバン株式会社:製品情報サイト
Apple Watch のバンドを今はブレイデッドソロループにしているのだけど、元々ゆる目のものを買って使っていたところ、昨今の体調のあれで手首が微妙に細くなってよりゆるゆるになってしまったので普通のベルトに戻そうか悩むところ。
]]>