TiarraのIRCログをBigQueryに流し込む
Created at:
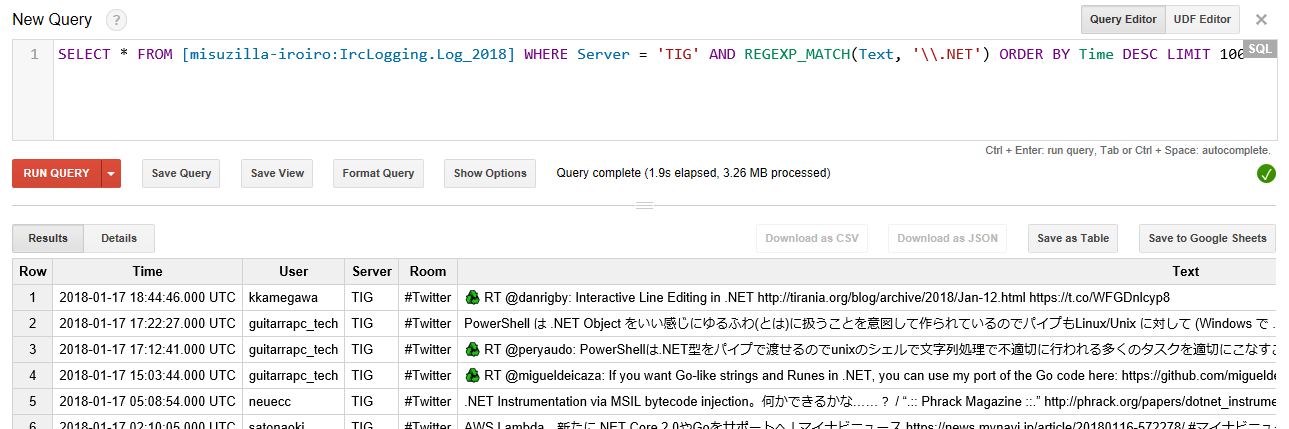
ふとTiarraでとったIRCのログをBigQueryに流し込むようにしたら手元にログを長期間残す必要もないし、検索もできるし便利そうだなと思ったので設定してみました。Twitterのログもあって若干流れますがBigQuery的には誤差の範囲レベル(1日1MB程度)なのでStreaming Insertして、たまーに検索しても無料枠で余裕で収まりそうです。
主な流れはTiarraで吐いたテキストログをfluentdのin_tailで読んで、fluent-plugin-bigqueryでBigQueryに流し込むという何の変哲もない形です。
Docker
ですでに手元のTiarraはDocker(docker-compose)で起動しているのでfluentdもDockerで起動しています。fluent-plugin-bigqueryはfluentdの公式イメージに追加する必要があるので適当に追加します。
|
ruby-bigdecimalが必要ということはREADMEにあるのですが、ruby-devとbuild-baseも必要で追加していないとfluent-plugin-bigqueryをインストール中にstrptimeのビルドで失敗します。
BigQuery Schema (schema.json)
次にBigQueryのスキーマを用意します。今回は次のようなものになっています。
|
テーブル自体はこのスキーマを使ってfluent-plugin-bigqueryに自動生成させるので、BigQuery側にはプロジェクトとデータセットだけ作っておきます。このスキーマファイルは次のfluent.confと同じところにおいてください(最終的にdockerでマウントされるところ)。
fluentd (fluent.conf)
最後にfluentdの設定です。
source(入力)はssig33 - Tiarra のログを fluentd で流すを参考にin_tailを設定します。手元ではTIGのログが流れてくるのとサーバー名を分解するために少し変更しています。ログはローテートされるので %Y.%m.%d.txt で。
出力はfluent-plugin-bigqueryの設定を auto_create_table で設定します。これ自体は何のことはない設定なのですが table を年で分けるようにしようとしたところでハマりました。
table にはプレースホルダ文字列を使えることになっているのですが、文字列置換が有効になる条件としてまず buffer time/timekey を設定しているというものがあります。そこで timekey を設定すると %Y ではなく %d 精度のプレースホルダを持つ設定を要求します(参考: output.rb)。しかし今回は%Yでいいのに…困った…と考えた末に fetch_schema_table という使っていない設定項目に log_%Y%m%d 入れて回避しました。
とはいえ真面目にBigQueryを使うレベルなら日別にすると思うので(扱いづらいし…)罠にははまらないとは思います。日付パーティションにしてもいいかもとか頭をよぎりますが量も大してないので最悪あとで何とかすればいいでしょう(適当。
|
あとはこれでfluent/fluentd-docker-imageを参考にDockerでマウントしつつ起動すればログがBigQueryに良しなに送られます。便利。